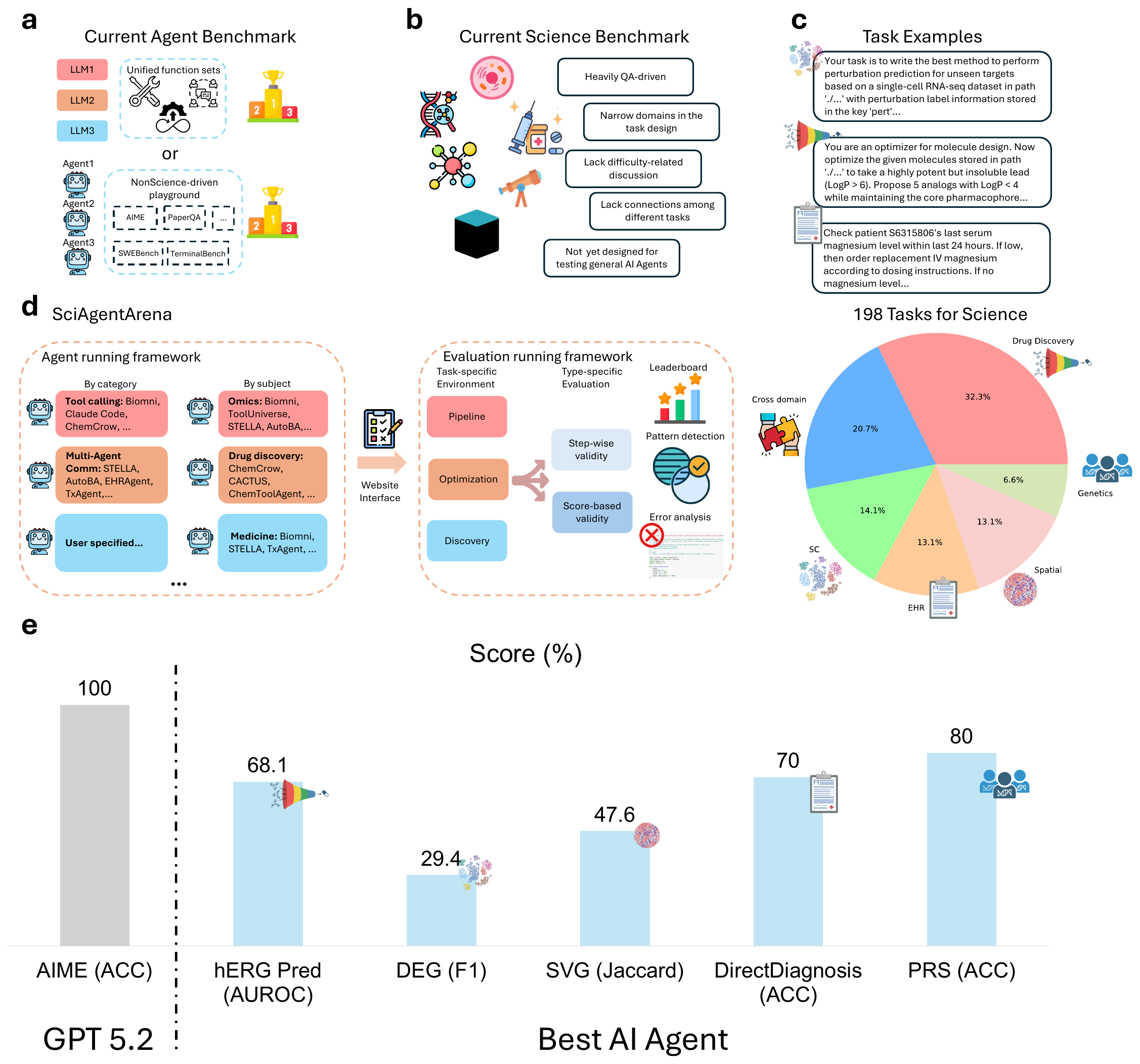
A Living Benchmark for AI Agents in Science
SciAgentArena
Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
Tianyu Liu, Allen Xin Wang, Antonia Panescu, Lisa Xinyi Chen, Wenxin Long, Xinyu Wei,
Yueqian Jing, Ziyao Zeng, Jihang Chen, Sihan Jiang, Ziqing Wang, Siyi Gu, Siyu Chen, Xinyang Hu,
Haoran Shao, Leqi Xu, Wangjie Zheng, Zhiyuan Cao, Ada Fang, Botao Yu, Oliver Sun, Rex Ying,
Arman Cohan, Qingyu Chen, Lingzhou Xue, Kaize Ding, Yuanqi Du, Wengong Jin, Zhuoran Yang,
Marinka Zitnik, James Zou, Hua Xu, Hongyu Zhao
Yale University · Broad Institute of MIT and Harvard · Penn State · Stanford · Northeastern ·
Northwestern · Harvard · Ohio State · Microsoft Research New England · UC Berkeley